
Projects
Recurrent Neural Processes for Spatiotemporal Prediction (MS Thesis)
Advisor: Prof. Katia Sycara, Robotics Institute, CMU
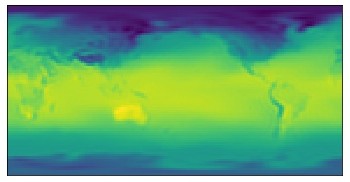
This was my Master’s thesis at Carnegie Mellon University. I proposed Recurrent Neural Processes (RNP), a deep latent variable model for spatiotemporal prediction with uncertainty estimation. The model combines the flexibility of neural processes — which learn a distribution over functions from context observations — with recurrent temporal dynamics, enabling predictions over space and time from sparse, irregularly sampled data. RNP captures both epistemic uncertainty (from limited observations) and aleatoric uncertainty (from inherent noise), providing calibrated uncertainty estimates alongside predictions. We evaluated RNP on multiple spatiotemporal benchmarks and demonstrated that it outperforms Gaussian Process-based baselines in both prediction accuracy and uncertainty calibration.
[Thesis]
Learning Hierarchical Policies in Dynamic Environments
Advisor: Prof. Ruslan Salakhutdinov, School of Computer Science, CMU

This project tackled the challenge of solving sparse-reward locomotion tasks in dynamic environments where terrain friction and agent morphology vary unpredictably. We proposed a hierarchical meta-RL framework that combines MAML-based skill learning at the lower level with a high-level master policy that selects and composes these skills. The lower-level sub-policies are meta-trained across a distribution of environment configurations, enabling rapid adaptation to new dynamics at test time. The high-level policy learns to sequence these skills to navigate complex maze-like environments. We demonstrated that MAML-trained sub-policies achieve up to 2x higher task success rate and significantly fewer steps compared to pre-trained policies across challenging environment configurations.
[Report]
Deep Reinforcement Learning for Sparse-Reward Manipulation Problems
Advisor: Prof. Matt Mason, School of Computer Science, CMU
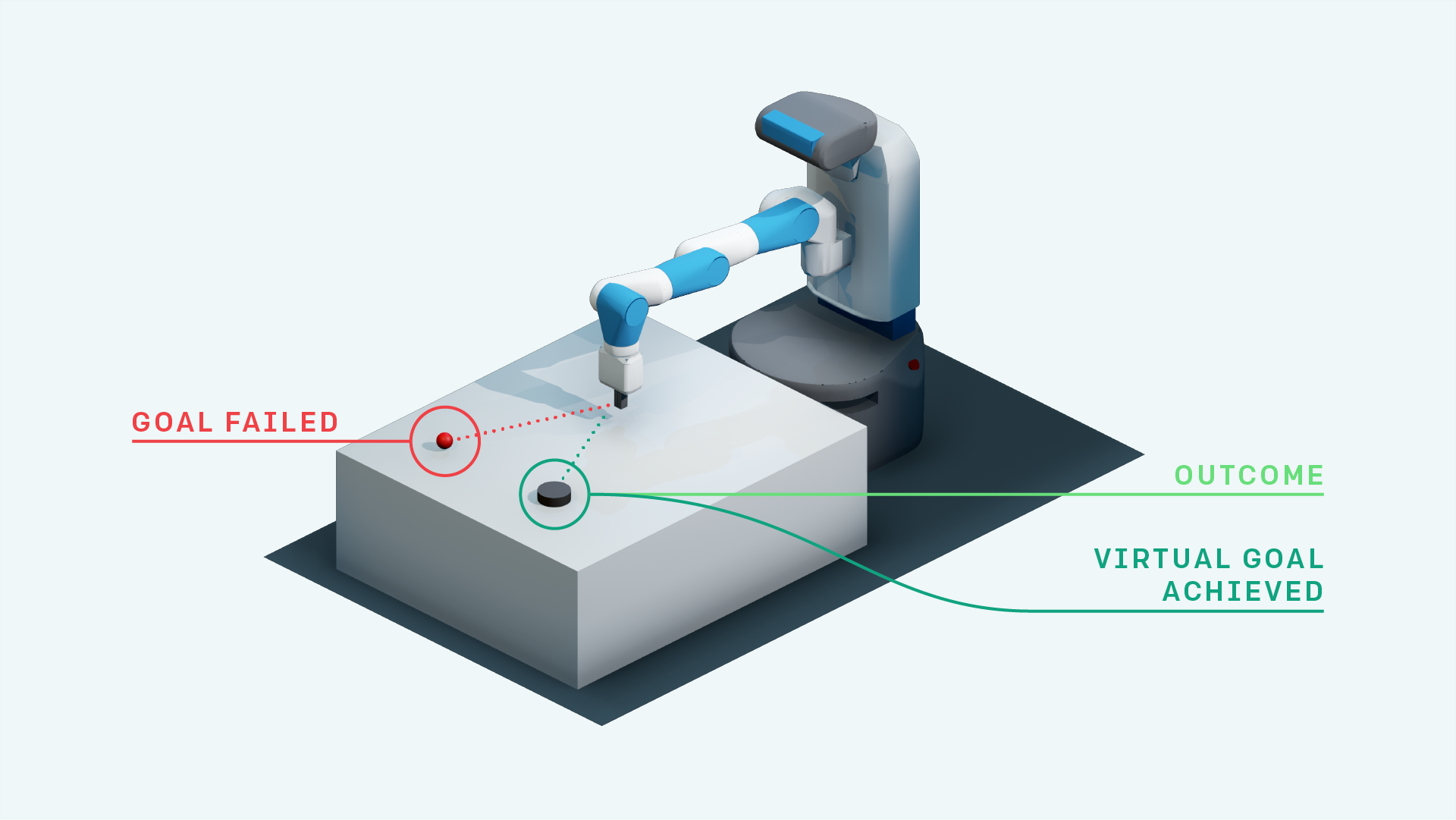
In multi-goal robotic manipulation tasks, sparse reward signals make learning extremely difficult — the agent receives no useful feedback until it accidentally achieves a goal. Hindsight Experience Replay (HER) addresses this by relabeling failed trajectories with achieved goals, but treats all replayed transitions equally. We proposed Prioritized Hindsight Experience Replay (PHER), which combines HER with TD-error-based transition prioritization and importance sampling to focus learning on the most informative transitions. We evaluated PHER on 7-DOF Fetch robot manipulation tasks in OpenAI Gym, including pick-and-place and push, demonstrating improved learning speed and higher task success rates compared to standard HER.
[Report]
Estimating Configuration Space Belief for Motion Planning
Advisor: Prof. Siddhartha Srinivasa, Personal Robotics Lab, CMU

During a summer research internship at the Personal Robotics Lab at CMU, I worked on reducing the computational cost of collision detection in high-dimensional robot motion planning. I proposed a probabilistic belief model over the robot’s configuration space that leverages results from prior collision checks to predict the collision state of unevaluated configurations. The approach exploits the continuity of configuration space — neighboring points tend to share the same collision state — using kNN methods and topological C-space structure to efficiently identify collision-free configurations. The proposed topological method outperformed traditional kNN approaches by achieving higher accuracy while being computationally efficient, reducing the expected number of collision checks needed during planning.
[Paper]